Change with growth is inevitable. And here at CSTA growth abounds! We are very excited to share some changes with you regarding our publication, The Advocate. As Board Liaison to the Publications Committee, I have the honor of sharing these changes with you.
The Advocate is moving! We will no longer have an independent site where we publish the blog posts. The Advocate will be moving to the csteachers.org domain and will become a segment of CSTA’s The Voice, under the direction of Stacy Jeziorowski. I will continue to moderate the blog and publish links to the articles in your favorite Facebook groups and on Twitter and LinkedIn.
The Advocate has served as a place for the CSTA Board to share exciting things that are happening at CSTA and in their CS-related areas of expertise. We, as a Board, will continue to provide in-depth looks at various aspects of CS education, with occasional special guests.
Please take the time to read through old posts, catch up on new ones, and enjoy our insights into CS education. The CSTA Advocate Blog as you know it will be open for a short while longer, at which time we will move our posts over to csteachers.org. Thank you for all your support and interest. We look forward to seeing you at CSTA 2020!!
I have some very exciting news from CSTA to share-out with all of you! Recently, Jake Baskin, our Executive Director for CSTA, announced on the Voice that CSTA, in partnership with the California Reading and Literature Project (CRLP), UC-San Diego’s Center for Research on Educational Equity, Assessment, & Teaching Excellence (CREATE), Education Studies Department (EDS), and the San Diego Education Research Alliance (SanDERA housed in the Economics Department), were awarded a $3 million dollar grant to address the equity gap for English Learners (ELs) in taking AP CS Principles courses.
For the past 30 years, I have worked at Sweetwater High School and for the Sweetwater Union High School District in National City and Chula Vista, CA. The high school and district I work for have large, significant populations of both ELs and reclassified ELs, and, from my personal perspective, I have observed the lack of educational opportunities for EL students to take rigorous and engaging academic courses such as Advanced Placement (AP) courses including AP Computer Science Principles (AP-CSP).
Some of the main reasons I was drawn into teaching high school AP (and non-AP) computer science courses were to provide equity access and to broaden participation of underserved and underrepresented groups in CS, which include women and students of color; but as the grant proposal argued successfully, the “opportunity gap in CS for ELs are even more profound.” The number of ELs taking AP courses are very low (7%) and ELs enrolled in AP CSP are significantly lower; for example, only 5% of students enrolled in AP CSP courses across the state of New Mexico are identified ELs and the numbers are similar for the region of San Diego County in Southern California and the state of Arizona.
I have met and taught many EL and reclassified EL children throughout my teaching career (I am a credentialed bilingual teacher). I specifically target and recruit EL students to take the AP CSP course in my high school and throughout the Sweetwater Union High School District. EL students can and are successful if EL pedagogy and strategies are embedded and implemented in the classroom. EL students can and will make significant contributions to our society, nationally and globally, in the field of CS and will help our society solve critical problems if given the opportunity to become part of the CS community. This work begins by recruiting and supporting EL students to take and successfully complete AP CSP as well as other CS courses.
Recognizing that current and former EL students are a profoundly underrepresented and underserved subgroup in Computer Science, CSTA, CRLP, CREATE, EDS, and SanDERA formed a partnership for this grant proposal and were awarded $3 million dollars to address this gap. With these resources, they aim to provide supports for schools and teachers to increase the opportunity for EL equity access and, thus, increase the number of ELs that are taking the AP CS Principles (AP CSP) course specifically
Although there are significant institutional barriers for ELs to have the opportunities to take and engage courses with rigorous academic content, such as having their schedules pre-determined with ELD courses, entering and exiting the ELD program by being reclassified, “research demonstrates that ELs fare better linguistically and academically” when taking rigorous courses such as the AP CSP course.
Additional significant barriers that exist in this opportunity gap for ELs to take AP CS Principles is the lack of supportive teacher professional development for those teaching ELs. Also absent is adequate CS curriculum that has EL pedagogy integrated and embedded within it. CSTA, CRLP, CREATE, EDS, and SanDERA will work in partnership to design and develop PD, training, and CS curriculum that has integrated and embedded in its foundation and core EL pedagogy and strategies, and to evaluate the program’s impact on teachers and students.
This PD, training, and CS curriculum will be targeted for the aforementioned three states: San Diego County in Southern California, Arizona, and New Mexico. Offered for the first time this summer 2020, the week-long PD, following-up training and EL-AP CSP adapted curriculum will launch in the three aforementioned communities/regions. Later, all resources will be made available to CSTA chapters across the states, which will help form Professional Learning Communities that will use the training and EL-AP CSP resources for the benefit of our EL children.
I feel that it is very important to mention that CSTA, specifically Executive Director Jake Baskin and the CSTA team, in partnership with my colleagues and good friends whom I have worked with over the past several years with AP CSP and Computer Science Education space: Associate Director Susan Yonezawa of UC-San Diego’s CREATE; Education Studies professors Megan Hopkins and Beth Simon, Economics Professor Julian Betts, who is also the Director of SanDERA and, and the team from the CRLP led by Executive Director Debbie Costa-Hernandez, has formed a partnership with our local CSTA chapter and several in Arizona and New Mexico toto address the gaps in equity, gender, and diversity in CS through the work proposed in this grant.
I am truly excited to work with all of these people and organizations to attempt to address and decrease the equity gap and increase the number of EL students that are taking AP CSP, and to share the training and resources developed through this grant with our CSTA chapters and you, our members of CSTA!
Contributions to this post were made by Dr. Susan Yonezawa of UCSD CREATE, CSTA Executive Director Jake Baskin’s Post on the Voice, and the proposal itself; thank you all!
I often hear comments like those below when I talk about teaching programming in Kindergarten through 2nd grade.
“Kindergarten students can’t program. They aren’t reading.”
“How can they program when they can’t type yet?”
“Is it even age-appropriate to ask primary aged students to program?”
You would think these comments would be from people who do not work with students in these grades, but that is not always the case. Computer science and programming can be scary to teachers who have not been trained in what CS is and what it looks like for 5-8 year old students.
One of the most common misconceptions I run into about programming in K-2 is that programming looks like this:
class HelloWorld
{
public static void main(String args[])
{
System.out.println("Hello, World");
}
}
Yes, that is programming but that kind of programming would not be age-appropriate for primary grades. Fortunately, programming does not look like that for 5-8 year olds.
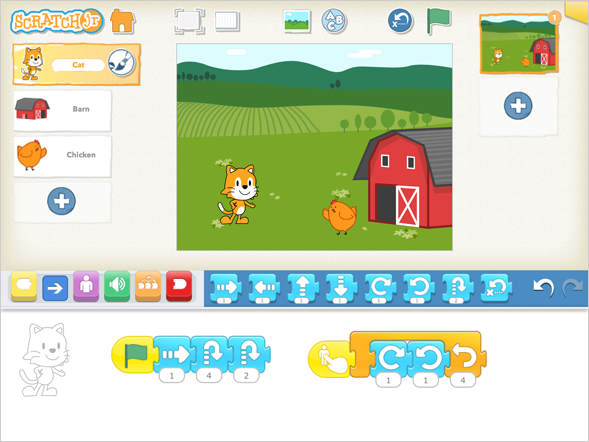
Programming in K-2 is ….
Visual and block-based
Hands-on and not necessarily on a screen
All About Sequencing … Sequencing is an important skill for students in all curricular areas. In reading, sequencing is the ability to recognize the beginning, middle, and end of a story along with being able to retell the events in the proper order. In math, sequencing is important for counting, pattern recognition, and the order in which computation should occur. In science, sequencing is important when conducting experiments and in social studies, sequencing helps students to understand the order of events. Learning to program reinforces the idea of sequencing since programs run in sequence and the order in which code is organized determines what happens in a program.
Cross-Curricular … Programming in primary grades is often cross-curricular. There are so many ways students can use programming to show what they know across the curriculum. Here are just a few ideas:
Use robots to:
Identify and spell words (sight words, word families, vocabulary)
Retell stories
Show math knowledge: for example, roll dice and have students add or subtract values and then program a robot to the correct answer
Navigate a map
Illustrate a lifecycle
Write programs in ScratchJr (or in Scratch, if students are reading) to:
Tell an original story
Animate a lifecycle
Tell about an animal or an important person
Animate a word problem in math
Programming in K-2 is also collaborative and creative and teaches students to problem solve and persevere. So, yes, learning how to program is age-appropriate and beneficial for K-2 students and yes, they can do it!
“Don’t tell me what things look like. Tell me what things are.”
Yes, I know I just mixed quotes, but let’s get to the point, and it is not to discuss The Child (AKA Baby Yoda). This blog was supposed to come out around the first of December, but I requested that I be able to delay it until after Computer Science Education Week, because I knew that I would want to highlight our announcements during that week and also speak to the state’s 5-year report on the #ARKidsCanCode / #CSforAR Initiative that was just released in early January.
CS Education Week 2019 (CSedWeek) was again a great success in Arkansas. In the past years, we had made it a point to make one announcement each day of the week. This year we started early, with a Gubernatorial kickoff on Friday, December 6th, and had multiple announcements each day of the following week. While I will not discuss them all in this blog, I invite you to go view the full listing and details at http://bit.ly/ARCSedWeek. However, I do want to highlight a few of the announcements.
One of the reasons for Gov. Asa Hutchinson wanting to personally acknowledge CSedWeek by means of a press conference, was that he, by executive order, reestablished our advisory CS taskforce. The newly titled Computer Science and Cybersecurity Task Force, is the natural progression of the Arkansas Computer Science and Public Technology Task Force, that was established in 2015 by legislation and sunset in 2016. The original task force provided our state and my office with the guidance and suggestions that have shaped our computer science (CS) initiative over the past five years. The reestablished CS task force will be chaired by Gov. Hutchinson’s Deputy Chief of Staff Mr. Bill Gossage, who also carried and championed the 2015 computer science legislation that established the mandate that all Arkansas high schools offer CS, is held up as a model by Code.org, and put Arkansas on the right pathway to lead this crucial educational initiative. This new task force, which had its first meeting on January 8, 2020, will “provide guidance on improving and establishing updated large-scale goals and strategies; industry pathways and relevant certifications for major areas of computer science and computing; post-secondary alignment strategies and goals; work-based learning opportunities for students; teacher credentialing; correct placement and focus on data sciences and cybersecurity in curricula; potential funding usage and future needs; and outreach and development of educational materials.”
In addition, our office made two large scale announcements with three of our post-secondary institutions and other partners. The first was that we would be partnering with the Arch Ford Education Service Cooperative’s Virtual Arkansas division, the University of Arkansas at Little Rock, and the University of Central Arkansas at Conway to develop a three-year cyber security curriculum and course pathway that will be available to Arkansas public school students at the beginning of the 2020-2021 school year. The second was that the Arkansas Department of Education, Arkansas State University, and the Arkansas Public School Resource Center would partner to provide a statewide online coding curriculum starting with the fall 2020 semester. The first offering of its type to the high school students of Arkansas, the UpSkill program is designed to support the Governor’s initiative on computer science skills. The course structure leads students through a nine-month curriculum that prepares them to receive a certificate in Swift coding.
Our state and my office again demonstrates our commitment to CSTA. Not only are we continuing to fund CSTA+ membership for Arkansas educators that are CS Certified, but we again increased our commitment to the CSTA Annual Conference. This year we are increasing the number of available sponsorships to 35 and doubling the reimbursement amount to $2000. Arkansas, and I personally, place a high value on the benefits CSTA and its annual conference provides to its members; this announcement renews and puts funding behind our commitment and support.
The last announcement I want to highlight before I get to the recently released report is the creation of the Arkansas Students of Distinction in Computer Science Recognition Program. Through this program, up to 50 public, private, and homeschool, students currently in grades 11 or 12 will be recognized for their efforts in computer science education.
“Cracking the Code: How Arkansas Became a National Leader in Computer Science & Computing” (http://bit.ly/2020CSforARReport) is Arkansas’s 5-year report on the history, efforts, successes, and future of our state initiative. When we started internally discussing the need for such a report, I wondered and asked aloud, why wouldn’t we just wait on the new task force report? I am now happy that my leadership pushed back on my question and helped me see that the audience for these two reports is not the same. Once I was onboard, as many of you know about me, I couldn’t just do it in a straightforward fashion… we all have enough “governmental looking” reports to drown in. So, when I started working with Eric Rob & Issac (https://ericrobisaac.com/) of Little Rock to help us create the report, I told Rob in an early meeting, I want something “different,” and let me tell you they produced something that met that request.
I was sitting in my office one day about a week after that first meeting, and Rob asked if he could stop by and show me something. I knew we were going to talk layout, but what he brought me, I couldn’t have imagined. He first showed me a more straightforward layout proposal, which was wonderful, but looked like any of 100 other governmental reports. Then he said, “I have something else to show you, but I want to know first how crazy you want to go on this.” I responded, “let’s see it.” What he pulled out of his bag looked like a paper computer complete with logo stickers, scuff marks, and other telltale signs that this “computer” belongs to our community. I immediately fell in love with it. As we talked about how the sections could be designed, I got more excited. Toward the end of the meeting, Rob looked at me and said, “So which one are we going with? Or do you need to get back with me?” Rob knows I have leadership that I have to answer to; however, this is one of those times I took a gamble and decided instantly to go with the “out there” option. I am happy to report, I still have a job, and my leadership also loves the design. While our office provided all of the information, Rob’s team did a great job in turning that extremely long text dense document into something that is informative but also fun to digest.
So, what does all this mean and why am I sharing it? Well first, as I said in one of my previous blogs, I do enjoy bragging on my state and our initiative, but it is more than that. It is meant as an example and challenge to the greater CS education community leaders and decision makers. We can not stop! We can not be content! We must continue to engage our community partners, look to expanding our efforts beyond K-12, and press on with the “new”, the “out there”, the “crazy”, and the “different.” Otherwise, this will just become another fad that fades into the ever increasing list of educational initiatives that like a sparkler in the night, flares up, burns brightly for a time, but then as quickly dies and, to the viewer, leaves the scene darker than it was before. “I have spoken.”
At last summer’s CSTA Annual Conference, Executive Director Jake Baskin announced the launch of a nationwide Computer Science Honor Society, building off of the success of CodeVA’s work in Virginia. The response from schools has been strong: to date, 128 schools across the United States have already set up a CS honor society.
This national program supported by CSTA helps high schools offering CS courses to grow and gain visibility for their CS programs, while fostering enthusiasm for computing and recognizing academic achievement among CS students. Honor societies promote the core values of equity, service, and excellence — recognizing that any student has the potential to grow and excel in computing, empowering members to become ambassadors of CS through community service, and promoting scholarship in CS coursework. If your school has not yet established an honor society, there are many reasons why you should consider doing so.
My last CSTA Advocate post “7 things for CS teachers to know” shared the themes cited by Google employees about how their school teachers created positive CS learning environments. These included encouraging and recognizing students, making CS concepts relevant, and promoting collaboration among peers. Through a CS honor society, you can act on all of these themes and provide an outlet for what students learn in class, making the learnings real and applicable. Honor societies can also help instill a sense of belonging and community among students excited about CS.
Specifically, the community service component of societies offers unique opportunities for students to serve as role models and peer instructors to others, which helps to retain student interest in computing and broaden access to CS learning opportunities to more students. Recently, in celebration of CSEdWeek, CSTA and Google partnered to sponsor CS honor societies in hosting Hour of Code sessions in their schools and districts. Over 800 society members from more than 30 honor societies participated, using CSTA’s CSEdWeek Outreach Toolkit to share introductory CS experiences with over 11,000 elementary, middle and high school students. You can find photos from some of these events on Twitter. One of my personal favorites was this video from Henrico County Public School showing student-led activities using Code.org’s Hour of Code, Microbits, and offline lessons to teach binary. If you’re thinking about establishing a Computer Science Honor Society at your school, know that CSTA provides support through sharing best practices, resources, sample service projects, student recruitment materials, and more. Learn more about how to get started here.
This fall, I taught an undergraduate class (at the University of Colorado Boulder) on Computing, Ethics and Social Responsibility. It was a wonderful experience. I think there are some lessons from this experience that are relevant to high school teachers who are thinking of introducing some discussion of issues in ethics and computing into their courses, even if just a few classes or portions of classes are devoted to this topic. There also is an increasing awareness that these sorts of issues shouldbe introduced to students studying computer science in high school. So, a few reflections:
There are lots of interesting topics. My course included discussion of: internet privacy, including targeted advertising and the Right to be Forgotten; internet security and hacking; facial recognition; misinformation; impacts of internet and social media on our lives, particularly those of young people; algorithmic bias; gender and race in algorithms, and in the computing industry; use of robotics in eldercare and in warfare; autonomous vehicles; medical and healthcare applications of computing; and the impact of computing technologies on the future of work. Certainly there are some topics in that list that would interest you and your students!
The best resources are recent media articles. And there is no shortage! You can easily populate a few classes from what pops up in your newsfeeds in recent months. There also are ways that you can find references that other people have used. One approach is to go to this crowdsourced listof courses in tech ethics and look at the references used in some of those courses. There is work in progress in ACM aimed at organizing a repository of links to such articles.
Students are interested. My experience was that there was plenty of interest and enthusiasm from students for these topics, particularly ones that related to the students’ experiences and interests. One example is how sites such as YouTube, or any site with ads, decide what to recommend to us next – everyone has experienced that and wondered about it a little. Robotic applications are another – everyone wonders what’s coming in their lifetimes.
The students’ perspectives may be different than yours. An example in my course was discussions of privacy and surveillance; the famous 1999 remark of Sun Microsystems CEO Scott McNealy, “You have zero privacy anyway. Get over it.”, seems to have become much closer to the reality of the current younger generations.
Small group discussions are particularly effective. The students got energized about discussing a particular topic or an article they had read and then summarizing their small group discussions with the full class. Groups of 3-5 students and 10-15 minute discussions seemed to work well.
Short written assignments are effective. This is a nice opportunity for students to be resourceful by finding a recent article related to ethics and computing on their own, and submitting a short summary and reflection on it.
There is a field called philosophy. Most undergraduate courses in this area introduce several philosophical theories, most commonly deontology, act utilitarianism, virtue ethics, and sometimes social contract theory. This may not be feasible in a briefer coverage in high school, but it may be good to make people aware that theories like this underlie a careful treatment of these topics.
Happy first CSTA blog post for 2020! Each year I try to reflect on the past year to help gain perspective for the next. When I think about CSTA and 2019, I have a warm and fuzzy feeling inside. It’s been a wonderfully success year for CSTA – from the conference in Phoenix to the amazing volunteers to the fabulous new additions in our staff to the increase of CSTA chapters across the country! WOW! Great job, everyone!
What people often don’t realize is the amount of hard work that goes on behind the scenes. Our volunteers are an essential part of what makes CSTA a growing, vibrant organization. A couple of the people who have greatly contributed to the fabulous 2019 are Fred Martin and Jen Rosato – they are the past and current chairs of the CSTA Board. They started as volunteers and have demonstrated their passion for K-12 computing education and our community. I have been lucky to be on the Board while Fred and Jen have been in leadership roles. I admire their inclusiveness and willingness to listen. I enjoy the way they organize and run meetings. And I greatly appreciate their many hours of work to help CSTA become an organization that benefits K-12 computing teachers.
As we start a new year, we will be deciding on how to spend our “free” time. There are many worthy organizations and activities we can join. They all need great volunteers. If you haven’t been a CSTA volunteer before, I highly recommend you consider trying us out! If you’re already a volunteer, be sure to keep up with all of the new activities that you may want to participate in! You don’t need to give up sleeping to volunteer – join your local chapter and participate in local activities, share something you’ve learned with another teacher. Be a part of CSTA family! (We’re really fun!!)
By Dan Blier, CSTA Board of Directors (District Representative)
One main purpose of computer science education is to prepare students for industry. Without industry partnerships, our CS programs may not be preparing students for the workplace. As part of my responsibilities of building and support a Pre-K through 12 grade CS program, I work with several industry partners.
As we prepare students for future jobs, we also need to
better understand what companies, who will be hiring our students, need. We must push past teaching only programming
syntax. Students must be able to
collaborate with others and come up with creative solutions to various
problems. In one conversation with an
industry partner, we asked what issues they see from newly hired computer
science majors. Some issues were simple
things like not showering to go to work.
However, other issues were more concerning. New hires are attending planning meetings and
not engaging by asking questions. They
return to their desk lacking clarity of their assignment because of this
issue. We must provide students opportunities
to engage with each other and to feel comfortable asking questions in a group
or classroom environment.
Our district has worked with several locally-based industry partners such as USAA, Finastra, Capital One, Texas Instruments, Boeing, Toyota, Amazon, and JPMorgan Chase. These companies reach out with a variety of opportunities for their employees to engage with our students. When students have an opportunity to meet people who work in the field, students gain a better understanding of CS-related jobs. Some students would never know about these types of jobs without these experiences. Getting an opportunity to see what the workplace looks and feels like is an important part of CS education. Through these partnerships, students have been brought to these organizations to engage in coding activities while collaborating with employees. Hackathons are another great way for students to engage with industry partners while learning more about careers in CS. In other cases, industry partner employees have visited our classrooms to lead Hour of Code activities or other coding experiences. These employees are always asked to share something about their job with our students.
In some cases, teachers can participate in externships
during their summer break. Teachers in
the CS program have come back and shared their experiences with the rest of the
CS team and brought back industry knowledge to their classrooms.
Students will eventually have to interview for computer science positions in companies. One thing that has come up through our discussions with industry partners is that candidates go through what is called a whiteboard interview. The candidate may be interviewed with other candidates in a group situation. They may interview with a team of employees. Through the whiteboard interview process, candidates must show their ability to think on their feet, take their content knowledge and come up with a creative solution within the parameters set by the company, and engage with others. Some organizations are no longer requiring a bachelor’s degree for an entry-level employee. If we are to prepare our students for these entry-level jobs, we must prepare them for the interview process. Industry partners can be helpful in providing volunteers to come run students through such a process.
Whether you are in a metropolitan area like Dallas-Fort Worth or in a rural area, there are different ways to engage with industry partners. Organizations like TEALS (https://www.microsoft.com/en-us/teals) can help you connect with industry partners wherever you may live and work. Here are some other computer science career-related resources to check out.
There is a feeling when you are driving on the open road and just enjoying the flow of the traffic and you are just cruising and advancing at a constant pace, that is satisfying. Then, there is the feeling when you enter the big city, at peak traffic time, when you feel you are never arriving at your destination and then you are stuck behind a nice sweet grandma driving. Well, these are feelings I have gotten to know well in my teaching life. Throughout my 19 years of teaching Computer Science, I have had the opportunity to teach all divisions from K-12 and all of them have their rewarding and challenging moments. This year I was asked to teach 6-8. I have to say that I am in my first semester and I have gotten a huge sense of respect for Middle School teachers.
When you teach Pre-school or Elementary you feel like you are getting bright new brains that are waiting to be filled in with new information. When you teach High School, you get kids that are going through the maturity process of finally getting that what they do in this stage will determine what they decide to do for their higher education. And then there is Middle School, that limbo stage of it all. That peak hormonal stage where kids are confused about everything. Their priorities change not only every day but several times throughout the same day. This has made me change and adapt to the way CS should be taught.
I had never had to modify so many
plans on the go as I have this year. You plan and plan and then somedays it is
the best lesson ever and somedays it just not. So how do middle school teachers
do it? I am relearning how to teach CS and I have a lot of help from my
colleagues in the same hallway. They have been the best induction to teaching Middle
School as no book or article can tell you how to best get these kids inspired
or show their creativity like another teacher doing the same, does.
My kids have achieved amazing projects, but in the process, I have learned who has a crush on whom, who is now friends with whom and just a plethora of gossip that I did not know had to be now part of my information bank. It is amazing that they can be programming a Micro: Bit, creating a videogame using Scratch, designing 3D models, all while socializing and sharing their lives both in-person and digitally. I now have a new definition of multitasking. I have also learned that even if they are doing this, as long as they are working, everyone is happy! Thank goodness for headphones. One of the most wonderful things is that this is the age where they don’t hide their passions for something and if I am smart, I use these snippets to my advantage and plan lessons accordingly. Keeps me on my toes. This is a crucial moment when I can open their minds to all CS has to offer, I just have to move all the other clutter in their heads to a side.
So I might not be driving at 70 MPH as I was when I was teaching High School but while driving at 55 MPH I can see what’s going on in this big city called Middle School and how these kids are shaping their lives and finding themselves one CS project at a time. Once again, my biggest applause and respect to all those Middle School CS teachers out there.
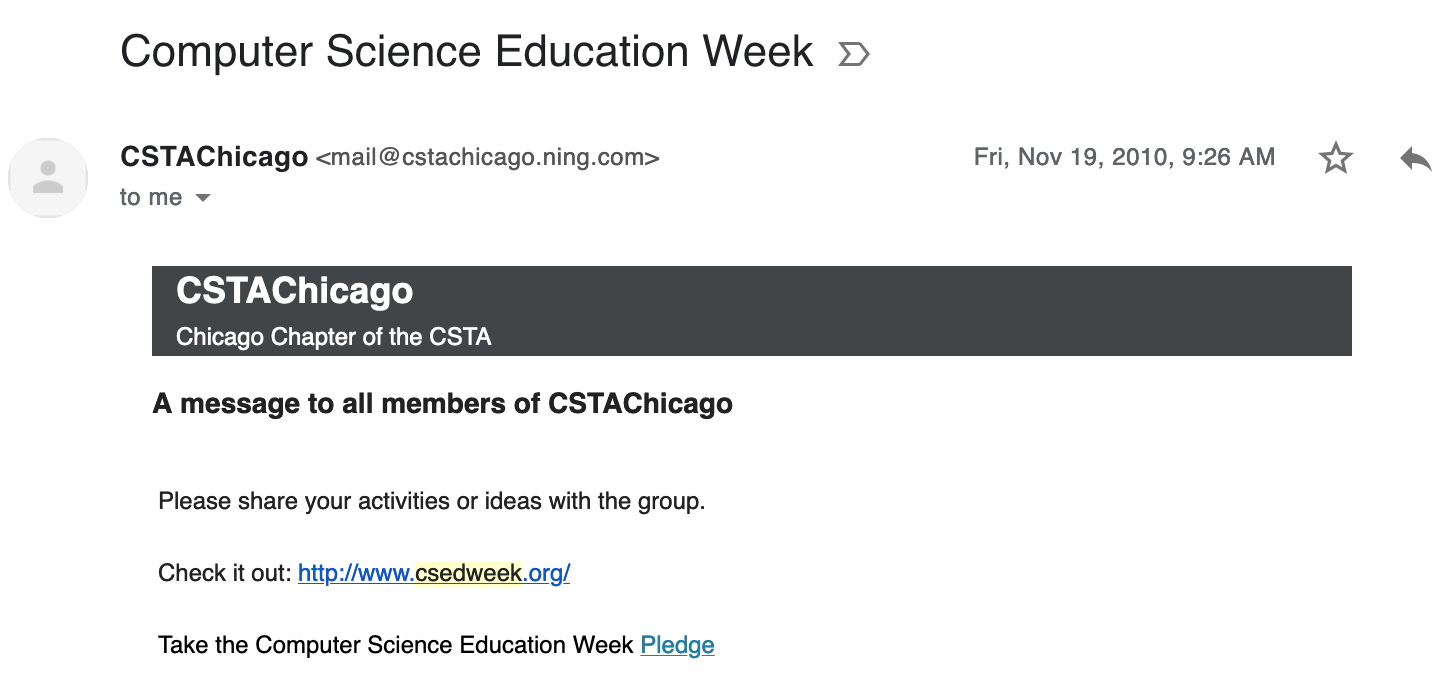
This December marks the 10th anniversary of Computer Science Education Week (CSEdWeek) and it’s remarkable how far it has come. I’ll be honest, I wasn’t a CS teacher during the first-ever CS Education Week, so I can’t claim to remember the full history, but thanks to the magic of unlimited email storage I can share the first email I ever got about CS Ed Week:
It’s no surprise that my local CSTA chapter was also my connection to the early days of this national movement. I know I proudly took the 2010 CSEdWeek pledge (not that I can remember exactly what the pledge was anymore). In 2011, I remember trying, unsuccessfully, to get my local alderman to get the Chicago City Council to officially proclaim CSEdWeek. Given the amazing momentum around CS education, it’s easy to forget that we’re building on a foundation built by passionate teachers, and I am so proud that CSTA has been there supporting teacher voices from the start.
That’s why I’m very excited that CSTA will be co-hosting this year’s CSEdWeek kickoff. We’ve partnered with Code.org and the Computer Science Alliance to launch CS Ed Week 2019 in Santa Fe, New Mexico, on Dec. 9 with an insightful panel discussion focused on this year’s theme — CS for Good — and the announcement of the 2019 Champions of Computer Science. For those of you who can’t make it to Santa Fe, we’ll be live streaming this event, so I encourage you to watch if you have the opportunity.
Behind the scenes at CSTA, our team has been developing new classroom resources honoring the CS for Good theme, including a set of posters that feature diverse people who use CS for Good in multiple industries. We’ll be releasing these as part of our CSEdWeek celebration, so make sure you’re following our social media channels to learn how to download the posters.
What happens in each of your schools and classrooms is what makes CS Ed Week most exciting. Please share what you do by tagging @csteachersorg in your Tweets and use #CSforGood #CSEdWeek in your posts.