Fred Martin is a faculty member at the University of Massachusetts Lowell, where he is associate dean for teaching, learning, and undergraduate studies in the Kennedy College of Sciences and professor of computer science. He has been serving on the board of CSTA since 2014, and is past-chair of CSTA's Board of Directors.
These headlines are from reputable news sources, including MIT Technology Review. Is it just me, or has the media decided that AI will cause the end of civilization as we know it?
I’d like to suggest that exactly the opposite is true. In fact, owing to technological innovations, the quality of life has improved immensely—across all of the world. For example, did you know that:
Over the last 200 years, the fraction of people living in extreme poverty has dropped from 85% (in 1800) to just 9% (in 2017)?
Over this same period, the average life expectancy—worldwide—has risen from 31 years to 72 years?
Since 1970, the fraction of people who are undernourished has dropped from 28% to 11% (in 2015)?
For all of us who are living reasonably comfortable lives, we owe this largely to the march of technologies which have made our lives massively better: providing abundant food, inexpensive clothing, affordable shelter, and sanitary plumbing.
Remember the Luddites? They were wrong. Machines have made our lives better. Representation of Luddites destroying a weaving machine, early to mid 1800s. Public domain image retrieved from Wikimedia.
What does this have to do with artificial intelligence? Let me suggest that AI is simply the current technology for building machines that are improving our lives.
Here are three big areas in which AI is making things better, right now: medicine, energy, and food:
These are all fabulously good, amazing things that are making our world better and improving people’s lives.
Of course, there are challenges. Technology causes disruptions in work, as work previously done by people is done by machines (see Luddites, above). AI will cause the same. People will lose their jobs. New jobs will be created, but it’s not clear that the people who lose their jobs will be the ones able to fill the new jobs.
These societal challenges are best resolved with engagement in consciousness-raising and political action.
We have already seen positive change stemming from recent concerns with AI systems. Just 18 months ago, it was headline news that face-recognition systems often misidentified women and people of color.
Thanks to the work of activist reporters and many others (including those who were most adversely impacted), it’s a widely known issue. An entire community has formed to address issues of “fairness, accountability, and transparency” in AI; this group holds an annual conference. Microsoft has withdrawn its facial recognition database in response to these concerns, and IBM Research released a “Diversity in Faces” dataset to advance the study of fairness in facial recognition systems.
This is exactly what we would want to happen in a democratic society.
While we combat social injustices, we must take the long view. Artificial Intelligence will be part of the technologies we build to advance humankind and all the species which populate our world.
Let’s not fear AI; let’s embrace it. AI will save the world.
Abstract: Artificial intelligence (AI) is automated decision-making, and it builds on quantitative methods which have been pervasive in our society for at least a hundred years. This essay reviews the historical record of quantitative and automated decision-making in three areas of our lives: access to consumer financial credit, sentencing and parole guidelines, and college admissions. In all cases, so-called “scientific” or “empirical” approaches have been in use for decades or longer. Only in recent years have we as a society recognized that these “objective” approaches reinforce and perpetuate injustices from the past into the future. Use of AI poses new challenges, but we now have new cultural and technical tools to combat old ways of thinking.
Introduction
Recently, concerns about the use of Artificial Intelligence (AI) have taken center stage. Many are worried about the impact of AI on our society.
AI is the subject of much science fiction and fantasy, but simply put, AI is automated decision-making. A bunch of inputs go into an AI system, and the AI algorithm declares an answer, judgment, or result.
This seems new, but quantitative and automated decision-making has been part of our culture for a long time—100 years, or more. While it may seem surprising now, the original intent in many cases was to eliminate human bias and create opportunities for disenfranchised groups.Only recently are we recognizing that these “objective” and “scientific” methods actually result in reinforcing the structural barriers that underrepresented groups actually face.
This essay reviews our history in three areas in which automated decision-making has been pervasive for many years: decisions for awarding consumer credit, recommendations for sentencing or parole in criminal cases, and college admissions decisions.
Consumer credit
The Equal Credit Opportunity Act, passed by the U.S. Congress in 1974, made it unlawful for any creditor to discriminate against any applicant on the basis of “race, color, religion, national origin, sex, marital status, or age” (ECOA 1974).
As described by Capon (1982), “The federal legislation was directed largely at abuses in judgmental methods of granting credit. However, at that time judgmental methods that involved the exercise of individual judgment by a credit officer on a case-by-case basis were increasingly being replaced by a new methodology, credit scoring.”
As recounted by Capon, credit scoring systems were first introduced in the 1930s to extend credit to customers as part of the burgeoning mail order industry. With the availability of computers in the 1960s, these quantitative approaches accelerated. The “credit scoring systems” used anywhere from 50 to 300 “predictor characteristics,” including features such as the applicant’s zip code of residence, status as a homeowner or renter, length of time at present address, occupation, and duration of employment. The features were processed using state-of-the-art statistical techniques to optimize their predictive power, and make go/no-go decisions on offering credit.
As Capon explains, in the years immediately after passage of the ECOA, creditors successfully argued to Congress that “adherence to the law would be improved” if these credit scoring systems were used. They contended that “credit decisions in judgmental systems were subject to arbitrary and capricious decisions” whereas decisions made with a credit scoring system were “objective and free from such problems.”
As a result, Congress amended the law with “Regulation B” which allowed the use of credit scoring systems on the condition that they were they were “statistically sound and empirically derived.”
This endorsed companies’ existing use of actuarial practices to indicate which predictor characteristics had predictive power in determining credit risk. Per Capon: “For example, although age is a proscribed characteristic under the Act, if the system is statistically sound and empirically derived, it can be used as a predictive characteristic.” Similarly, zip code, a strong proxy for race and ethnicity, could also be used in credit scoring systems.
In essence, the law of the United States ratified the use of credit scoring algorithms that discriminated, so long as the as the algorithms were “empirically derived and statistically sound”—subverting the original intent of the 1974 ECOA law. You can read the details yourself—it does actually say this (ECOA Regulation B, Part 1002, 1977).
Of course, denying credit, or offering only expensive credit, to groups that historically have had trouble obtaining credit is a sure way to propagate the past into the future.
Recommendations for sentencing and parole
In a deeply troubling, in-depth analysis, ProPublica, an investigative research organization, showed how a commercial and proprietary software system is being used to make parole recommendations to judges for persons who have been arrested is biased (Angwin et al., 2016).
As ProPublica reported, even though a person’s race/ethnicity is not part of the inputs provided to the software, the commercial software (called COMPAS, as part of the Northpointe suite) is more likely to predict a high risk of recidivism for black people. In a less well-publicized finding, their work also found that COMPAS was more likely to over-predict recidivism for women than men.
What was not evident in the press surrounding the ProPublica’s work is that the US has been using standardized algorithms to make predictions on recidivism for nearly a century. According to Frank (1970), an early and classic work is a 1931 study by G. B. Vold, which “isolated those factors whose presence or absence defined a group of releasees with a high (or low) recidivism rate.”
Contemporary instruments include the Post Conviction Risk Assessment, which is “a scientifically based instrument developed by the Administrative Office of the U.S. Courts to improve the effectiveness and efficiency of post-conviction supervision” (PCRA, 2018); the Level of Service (LS) scales, which “have become the most frequently used risk assessment tools on the planet” (Olver et al., 2013); and Static-99, “the most commonly used risk tool with adult sexual offenders” (Hanson and Morton-Bourgon, 2009).
These instruments have undergone substantial and ongoing research and development, with their efficacy and limitations studied and reported upon in the research literature, and it is profoundly disturbing that commercial software that is closed, proprietary, and not based on peer-reviewed studies is now in widespread use.
It is important to note that Equivant, the company behind COMPAS, published a technical rebuttal of ProPublica’s findings, raising issues with their assumptions and methodology. According to their report, “We strongly reject the conclusion that the COMPAS risk scales are racially biased against blacks” (Dieterich et al., 2016).
Wherever the truth may lie, the fact that the COMPAS software is closed source prevents an unbiased review, and this is a problem.
College admissions decisions
At nearly one hundred years old, the SAT exam (originally known as the “Scholastic Aptitude Test”) is a de facto national exam in the United States used for college admission decisions. In short, it “automates” some (or much) of the college admissions process.
What is less well-known is that the original developers of the exam intended it to “level the playing field”:
When the test was introduced in 1926, proponents maintained that requiring the exam would level the playing field and reduce the importance of social origins for access to college. Its creators saw it as a tool for elite colleges such as Harvard to use in selecting deserving students, regardless of ascribed characteristics and family background (Buchmann et al., 2010).
Of course, we all know what happened. Families with access to financial resources hired tutors to prep their children for the SAT, and whole industry of test prep centers was born. The College Board (publisher of the SAT) responded in 1990 by renaming the test to be the Scholastic Assessment Test, reflecting the growing consensus that “aptitude” is not innate, but something that can be developed with practice. Now, the test is simply called the SAT—a change which the New York Times reported on with the headline “Insisting it’s nothing” (Applebome, 1997).
Meanwhile, contemporary research continues to demonstrate that children’s SAT scores correlate tightly with their parent’s socioeconomic status and education levels (“These four charts show how the SAT favors rich, educated families,” Goldfarb, 2014).
The good news is that many universities now allow students to apply for admission as “test-optional”; that is, without needing to submit SAT scores or those from similar standardized tests. Students are evaluated using other metrics, like high school GPA, and a portfolio of their accomplishments. This approach allows universities to admit a more diverse set of students while evaluating they are academically qualified and college-ready.
What are the takeaways?
There are three main lessons here:
1. Automated decision-making has been part of our society for a long time, under the guise of it being a “scientific” and “empirical” method that produces “rational” decisions.
It’s only recently that we are recognizing that this approach does not produce fair outcomes. Quite to the contrary: these approaches perpetuate historical inequities.
2. Thus today’s use of AI is a natural evolution of our cultural proclivities to believe that actuarial systems are inherently fair. But there are differences: (a) AI systems are becoming pervasive in all aspects of decision-making; (b) AI systems use machine learning to evolve their models (decision-making algorithms), and if those decision-making systems are seeded with historical data, the result will necessarily be to reinforce the structural inequities of the past; and (c) many or most AI models are opaque—we can’t see the logic inside of them used to generate decisions.
It’s not that people are intentionally designing AI algorithms to be biased. Instead, it’s a predictable outcome of any model that’s trained on historical data.
3. Now that we are realizing this, we can have an intentional conversation about the impact of automated decision-making. We can create explicit definitions of fairness—ones that don’t blindly extend past injustices into the future.
In general, I am an optimist. Broadly, technology has vastly improved our world and lifted many millions of people out of poverty. Artificial Intelligence is presently being used in many ways that create profound social good. Real-world AI systems perform early, non-invasive detection of cancer, improve crop yields, achieve substantial savings of energy, and many other wonderful things.
There are many initiatives underway to address fairness in AI systems. With continued social pressure, we will develop technologies and and a social contract that together creates the world we want to live in.
Acknowledgments: I am part of the AI4K12 Initiative (ai4k12.org), a joint project of the Association for the Advancement of Artificial Intelligence (AAAI) and the Computer Science Teachers Association (CSTA), and funded by National Science Foundation award DRL-1846073. We are developing guidelines for teaching artificial intelligence in K-12. With my collaborators, I have had many conversations that have contributed to my understanding of this field. I most especially thank David Touretzky, Christina Gardner-McCune, Deborah Seehorn, Irene Lee, and Hal Abelson, and all members of our team. Thank you to Irene and Hal for feedback on a draft of this essay. Any errors in this essay are mine alone.
Buchmann, C., Condron, D. J., & Roscigno, V. J. (2010). Shadow education, American style: Test preparation, the SAT and college enrollment. Social forces, 89(2), 435–461.
Capon, N. (1982). Credit scoring systems: A critical analysis. Journal of Marketing, 46(2), 82–91.
Datta, A., Tschantz, M. C., & Datta, A. (2015). Automated experiments on ad privacy settings. Proceedings on privacy enhancing technologies, 2015(1), 92–112.
Frank, C. H. (1970). The prediction of recidivism among young adult offenders by the recidivism-rehabilitation scale and index (Doctoral dissertation, The University of Oklahoma).
Hanson, R. K., & Morton-Bourgon, K. E. (2009). The accuracy of recidivism risk assessments for sexual offenders: a meta-analysis of 118 prediction studies. Psychological assessment, 21(1), 1.
The field of mathematics is at least 5,000 years old; we can trace its origins to Mesopotamia [1].
Physics is at least 2,500 years old; in classical Greece, scholars knew the Earth was round [2].
Chemistry dates from about 250 years ago, to the late 1700s. Some consider the work of Antoine Lavoisier, “who developed a law of conservation of mass that demanded careful measurement and quantitative observations of chemical phenomena,” as marking the beginning of modern chemistry [3].
What about computer science?
We can go back to Charles Babbage, and his work on the Difference Engine and the Analytical Engine, beginning in the 1820s. That’s about 200 years ago [4].
The theoretical foundations for computing date from the early 1900s. These were established by the invention of the lambda calculus, by Alonzo Church in the 1930s, and the Turing machine formalism, by Alan Turing in 1936.
Fun facts: (a) Lambda calculus is a way of describing computations via compositions of mathematical functions. Understanding it provides an incredible insight into recursion, but doesn’t help you understand how to build a computer. (b) The Turing machine abstraction, on the other hand, describes a “tape” which has a linear series of memory cells, a “head” for reading and writing data to the cell underneath the head, and a set of rules for deciding what to do at each step and which way the head should move next. It’s a lot more like an actual machine (and hence its name). (c) Also, Alonzo Church (inventor of the lambda calculus) was the doctoral adviser of Alan Turing!
It was a decade after this work, in the late 1940s, that the idea of a stored-program computer was introduced, by John von Neumann [5].
I’d say these are the key moments in the history of the ideas behind computing.
When did computer science professionalize?
Another way of marking history is to look at professional organizations.
The Association for Computing Machinery (ACM) was founded in 1947 [6], and SIGCSE, the Special Interest Group for Computer Science Education, held its first annual Symposium in 1970 (next year in 2019 will be its 50th meeting!) [7].
At the university level, “departments of computer science” didn’t become widespread until the 1980s—about 35 years ago! [8]
Our own Computer Science Teachers Association was founded in 2004—meaning next year will be our fifteen year [9]. By comparison, the US-based National Council of Teachers of Mathematics (NCTM) inaugurated its first president in 1920—it’s nearly 100 years old! [10].
What about computing in K–12 schools?
Seymour Papert, with Cynthia Solomon, and others, did their foundational work on Logo beginning in the late 1960s.
In the United States, it wasn’t until computers like the Texas Instruments TI-99/4 (1981), the Apple IIe (1983) and the IBM PCjr (1984) shipped that computers started to enter schools in large numbers.
That’s also about 35 years ago.
Why does this history matter?
We need to remember that we all are the pioneers at the beginning of a vast intellectual and cultural journey.
At the higher ed level, what’s remarkable about computer science curricula is that smart minds don’t agree! Some CS departments start with Java and teach the machine late. Others start with C, introduce the machine early, and teach abstract principles late.
That’s just one example of the diversity in university CS curricula. There are many others.
Compare this to mathematics and physics. In those disciplines, everyone knows that the “correct answer” is to teach differentiation followed by integration (Calculus I and II) and mechanics followed by electromagnetism (Physics I and II). Practically every first year science and engineering student across the United States will take courses in that sequence.
Our field is nothing like this. We are still figuring out what works. (Probably, lots of sequences will work, and I personally hope that we never arrive at a “best” answer.)
In K–12, we are exploring integrating computer science into other subjects—for example, using modeling and simulation in understanding science.
Ours is the really exciting time. We should revel in being the pioneers—our work has the chance to set the direction in our field for a long time to come.
I am delighted to inform you that at the CSTA summer board meeting on July 11, 2018, Jennifer Rosato was elected as incoming chair of the board.
Jennifer Rosato, CSTA chair-elect
Jennifer (“Jen”) Rosato is Director of the Center for Computer Science Education at the College of St. Scholastica and an Assistant Professor in Computer Information Systems. She leads the Mobile CSP project, including curriculum and professional development for the AP CS Principles course. Rosato also works on teacher education initiatives, including integrating computer science and computational thinking in pre-service programs as well as a graduate certificate program for current teachers.
Jen began her term as incoming chair immediately upon the election results being announced; at next year’s summer board meeting, she will become chair and I (Fred Martin) will become past-chair!
Also at the board meeting:
Newly elected board members Kristeen Shabram (K–8 Representative) and Amy Fox (9–12 Representative) began their 2-year terms.
Elections were held for 1-year terms on the Executive Committee. Serving for 2018–19 will be Anthony Owen, Bryan (“BT”) Twarek, and Jane Prey.
Our organization is fortunate to have such accomplished, dedicated, and generous volunteers to help make CSTA great.
Thank you to all CSTA board members, and a special congratulations and thank-you to Jen Rosato.
I would like to congratulate the winners of CSTA’s 2018 Board of Directors elections.
We are delighted to welcome new board members Kristeen Shabram (K-8) and Amy Fox (9-12). We welcome continuing Board members Miles Berry (International), Anthony Owen (State Dept), and Michelle Lagos De Javier (At-Large). And we owe a big debt of gratitude to Chinma Uche, who is rotating off the board. Thank you, Chinma!
For more about our new and continuing board members, see http://www.csteachers.org/ElectionResults2018.
Over the past 18 months, I’ve had the opportunity to be part a team led by Joyce Malyn-Smith of EDC for her NSF grant, Computational Thinking from a Disciplinary Perspective. The project was inspired by earlier work that Joyce conducted with Irene Lee. (Irene is the creator of the Project GUTS curriculum for learning science and computational thinking via modeling and simulation).
In their work, Joyce and Irene interviewed a variety of practicing scientists to reveal how they used computing to do science. Through these interviews, they elaborated a variety of practices which include profound and creative uses of computing, often invented by the scientists themselves.
Since the publication of Jeannette Wing’s 2006 paper on computational thinking, our community has been engaged in a sense-making process: what exactly is it? The initial description of “thinking like a computer scientist” is a bit tautological—and not terribly helpful for someone who isn’t already a computer scientist.
I have personally been struggling with understanding the relationships among the broad categories of computer science, programming, and computational thinking. For example:
Q. Can you do computer science without programming?
A: Yes of course; we can analyze the complexity of a search algorithm, realize the need to use hashing to speed a table-lookup, etc.
Q. Can you do programming without computer science?
A. Probably. Beginners’ spaghetti code might be an example. “Hacking” in general suggests building things without an underlying theory (though there may be an implicit one). But let’s say yes to this too.
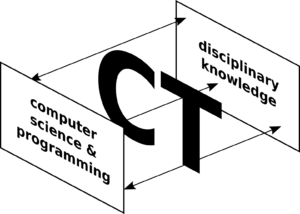
So, where does CT fit in? Is it in the intersection? Many people think you can do CT without doing programming, so perhaps not. How is CT not just another word for computer science then?
Venn diagram of programming and CS. Where does CT fit?
Jeannette Wing’s more recent paper (2011) provided this definition of CT: “Computational thinking is the [human] thought processes involved in formulating problems and their solutions so that the solutions are represented in a form that can be effectively carried out by an information-processing agent [a computer].”
To me, this still sounds like “thinking like a computer scientist.” This is what we do! We formulate problems and their solutions so that a computer can carry them out!
So what’s the difference between doing CT and doing computer science?
Thanks to my collaboration with Joyce and Irene (and our whole team), I now see an answer.
Computational thinking is about connecting computing to things in the real world.
Here are some examples.
A starter program we may often have our students write is to model a checking account. Our students will use a variable to represent the bank balance, and build transactions like deposits and withdrawals. Maybe they’ll represent the idea of an overdraft, or insufficient funds.
Let me argue that this simple example captures the essence of computational thinking.
What makes it so is that we are connecting a concept in the world—money in a bank account—to its representation in a computational system. This sounds pretty simple. But there is surprising complexity. What sort of numerics should we use—e.g., should we represent fractional pennies? For a beginning student, we could ignore this. But in a more elaborated solution, this intersection of computational considerations and real-world concerns is crucial—and this is computational thinking.
Here is another example. Consider how we usually represent colors. We use three bytes of information: 0 to 255 amounts of red, green, and blue (RGB) light. For web HTML, we’d use the hexadecimal notation. For example, #8020C0 is 128 (decimal) of red, 32 (decimal) of green, and 192 (decimal) of blue, or this color:
A purple swatch which is #8020C0.
This RGB representation was created at the intersection of the neurophysiology of human vision, the physics of how we build displays, and practical considerations of computing. Why do we mix only these three wavelengths of light? Because the way our eyes and brains work, we can mimic practically any color with just these three. Why use just one byte of information for each color intensity? It turns out the ~16 million colors which can be represented this way is quite powerful—and good enough—for how we use computers now.
So the whole notion of the RGB representation of color is computational thinking in action.
For a more elaborated example, let’s consider the JPEG file format—of the Joint Photographic Experts Group. This team included computer scientists, neurophysiologists, and artists. Their insight was that we could compress images by a factor of ten or more by discarding information that the human eye doesn’t see anyway. What a fabulous insight—and the very essence of computational thinking, because it connects concepts in computing (like compression algorithms) to understandings of our physical and perceptual worlds.
To revise our illustration, now CT is the “connecting tissue” between the world of computer science / programming expertise and the world of disciplinary knowledge:
Visualization of CT as “connecting tissue” between CS/programming and disciplinary knowledge of the world
To “do CT,” you need to know about both worlds. You need to know how to create solutions using computing. You need to know something about a domain in the world. And CT is the knowledge, skills set, and disposition of intermediating between these two.
Now, Jeannette Wing’s 2011 definition makes perfect sense: “Computational thinking is the thought processes involved in formulating problems and their solutions so that the solutions are represented in a form that can be effectively carried out by an information-processing agent.”
Yes! The key is recognizing that there is a non-computational domain—something in the world that we care about—which is being transformed (represented computationally) in this process.
To close the loop back to Joyce’s project: In addition to myself and Irene Lee, Joyce’s team had project advisers Michael Evans and Shuchi Grover, her EDC colleagues Paul Goldenberg, Lynn Goldsmith, Marian Pasquale, Sarita Pillai, and Kevin Waterman, and project evaluator David Reider.
In a series of planning meetings and then a pair of 2-day workshops with K-12 CS practitioners and researchers from around the country, we developed the idea of how computational thinking is transformed by connecting it to scientific disciplinary practice.
We created a framework with a set of five “elements” which illustrate the integration of computational thinking into disciplinary understanding.
Please stay tuned for work to come from our group, presenting this idea of “Computational Thinking From a Disciplinary Perspective.”
It’s given me a whole new way to think about what computational thinking can mean.
Now what are you thinking about? Of course, it’s an elephant.
This sentence is the title of a book by George Lakoff, a contemporary linguist who makes that case that we frame our thinking with the words and metaphors we use. By consciously recognizing this, we can understand our own thinking better and become more persuasive.
Inspired by Lakoff’s work, Alvaro Videla published an essay Metaphors We Compute By in the October 2017 Communications of the ACM. As a computer scientist and software engineer, Videla recognized the extent to which we make sense of concepts in computing via metaphors. He gives this example:
Say you could program a computer to command other computers to perform tasks, respecting their arrival order. This description is already difficult to understand. On the other hand, you could describe the solution by describing a queue server that assigns jobs to workers based on a first-come, first-served queue discipline.
Consider all the examples from daily life in the description of the solution: A “queue” is something with which all of us are familiar—that’s a “line” for those of us speaking American English! “First-come, first-served” is how most everyday lines operate, “workers” and “jobs” are people and roles from our daily lives.
With this metaphor, it makes sense. The everyday concepts translate into computational artifacts. A worker becomes an operating-systems process. A job becomes an algorithm carried out by that process on some particular data. The line becomes a FIFO queue.
This idea of using metaphors goes back far in our field. Some of the early CS education research focused on how the names of words chosen to be language commands helped (or hindered) students’ understanding. For example, in the 1987 article The Buggy Path to Development of Programming Expertise, Pea, Soloway and Spohrer reported on how students expected parallelism in BASIC code with “IF… THEN” statements. They thought the computer could evaluate any statement as needed, firing when a condition became true—as it might be in daily life.
I’ve used metaphors to explain function application—a concept in functional programming. It’s similar to how parameters or arguments are supplied to C or Java functions. I brought a rubber mallet to class, and described function application as the mallet “pounding the parameters on the head.” So if you have a function increment, which adds one to its parameter, then increment sees a 3, pounds it, and produces a 4. Then “functional mapping” is walking down a list, pounding each parameter in turn. In Scheme: (map increment (list 1 2 3 4)) produces the list (2 3 4 5).
Later during the semester, I could just pretend I was holding the mallet to bring back the idea of function application.
What metaphors have you introduced to your students to help them understand computing concepts? Did they work? Have you changed them over time? Please share with your colleagues!
How is computational thinking distinct from other thinking skills?
How can teachers assess computational thinking skills?
Have you ever wanted to ask an expert these questions? The CSTA Computational Thinking Task Force is creating a series of video interviews in which we do just that!
Listen in on our conversation with Chris Stephenson, Director of Computer Science Education Programs at Google, as she answers our questions and describes cross curricular computational thinking applications in the task of preserving native languages (https://youtu.be/FuN6g8NmuHc).
Listen to our conversation with Eric Snow, Education Researcher in the Center for Technology in Learning at SRI International as he answers our questions and describes his research in assessing computational thinking (https://youtu.be/92pv8dPItjE).
We have several more interviews with experts in the field planned for later this fall.
Spines of New Math paperbacks from the 1960s (courtesy wikimedia.org)
Many of us remember the New Math from personal experience. I do from elementary school in the 1970s in West Hurley, NY.
I loved it. I learned that the decimal system is arbitrary and numbers could be expressed in any base. That was fascinating.
Of course, I was the kid who learned his times tables for fun.
The New Math emphasized understanding the rule-systems that underlie numbers. In elementary school, it constructed the very concept of number with set theory rather than by rote counting.
There wasn’t a focus on students being able to do arithmetic computations. This upset people, and by the 1970s, the New Math was under attack.
The “back to basics” movement re-established an emphasis on computations in the 1980s.
As described by Christopher J. Phillips in his book The New Math: A Political History (The University of Chicago Press, 2015), it’s not a coincidence that this is the same decade in which the country elected Ronald Reagan as president.
Phillips cogently makes the case that the rise and fall of the New Math movement traces our cultural mores and larger political beliefs about who should be making decisions in our society.
Going back two thousand years, Phillips shows how the argument about how mathematics should be taught has been a proxy for a conversation about how people should be taught to think.
For the developers of the New Math, their approach would help American citizens be critical and creative thinkers—what was required to counter the Cold War threat of a dominant Soviet Union.
Indeed, the federal funding that was leveraged in the 1950s to build the New Math movement was appropriated as literally a matter of national defense. This was followed by the Elementary and Secondary Education Act in the 1960s, which continued the federal government’s role in fostering national education curricula.
The consensus that the federal government should be deciding what’s taught in our nation’s schools frayed with the cultural changes in the 1960s and collapsed with the horrors of Vietnam in the 1970s.
As we work towards making computer science a first-class citizen in the pantheon of school teaching and learning, what lessons can we draw from the rise and fall of the New Math?
Computer science is a liberal art—not just a vocational skill. It’s true that becoming accomplished as a software developer is a path to a good career, including good pay. And it’s true that there is a social justice dimension to broadening participation in computing—everyone should discover whether they love computing and then have access to these career paths.
But the reason to institutionalize computer science in K-12 is deeper than that. It’s because computing is beautiful and powerful—like all forms of knowing and doing.
We must go beyond the zero-sum game. One of our big challenges is creating time for teaching and learning computing. We don’t want to create winners (computer science) and losers (other areas of study).
It seems clear that infusion approaches—integrating computing into other subjects—will be an important part of the future.
It’s a team effort. One of the big take-aways from Phillips’ book was the reach of the School Mathematics Study Group—the organization that was created to develop and support the New Math. Curriculum writers from all over the country were involved in creating the reference texts; these individuals then served in leadership roles in the adoptions in their home states.
Most importantly, now we live in a time where everyone’s involved in curriculum decisions, particularly parents.
We need everyone together to make this happen.
P.S. I highly recommend Christopher Phillips’ book. His writing is clean and compelling, and the story is engaging and compact. He also published an essay-length version of his thesis in the New York Times on December 3, 2015.
This is a guest blog post by Kim Douglas, a student at UMass Lowell. Kim has a BA degree from Emerson College in Animation & Motion Media.
When people ask me what I’m studying, and I tell them that I’m pursuing a degree in computer science, they usually say one of two things.
“Oh, I totally should’ve done that. Tons of great-paying jobs in that field!”
or,
“Oh, I totally should’ve done that. But I’m not smart enough.”
I usually just smile politely and deflect, because these conversations tend to happen with adults who are well on their way, doing whatever they’re doing with their lives. But the truth is, responses like this frustrate me.
I wonder if the people with this first response are being earnest; whether their interest is for the right reasons. After all, everybody hates it when their favorite song becomes popular—especially if that song came from a collection of painstakingly curated mixtapes. I’ve only been programming for a few years, and still I feel this way.
Here I am, just halfway up the ladder to the neighborhood treehouse, and I already want to put up a “KEEP OUT!” sign for the kid behind me!
Then I think about how computer science makes me happy, and how it makes other people happy. Now, the second response—“Oh, I totally would’ve done that, but I’m not smart enough”—is even more frustrating. Because chances are, it’s just not true!
These people probably are smart enough, but got intimidated by the steep learning curve nonetheless. Yes, we should blame the media for that, but we should also blame ourselves. People start to see the KEEP OUT signs at a pretty young age.
Wait, come back! We need your hammer to fix our treehouse!
I am a researcher in the Middle School Pathways in Computer Science project, which is designed to make it so that Johnny who lives next door (and, in particular, Sally, Jane, DeShawn, Rudjit, Liliana, Esteban, and Amira) never see the KEEP OUT sign in the first place.
In my first week in project classrooms, an eighth grader—let’s call him Jake—asked me if I went to MIT. Understandable, since App Inventor has MIT literally written all over it.
“No, I go to UMass Lowell.”
“Can you make apps?”
“We make all kinds of cool stuff! So can you.”
“Nah. I’m not smart.”
Inside, I hang my head. I show him a demo app I had made in the fall, as part of the teachers’ professional development. It has pictures of some planets whose buttons play audio files and change colors when you press them. It’s no Candy Crush, but Jake is visibly more interested in it than the text-to-speech button he’d just made.
“Of course you’re smart. You can totally make something like this.”
“I can’t. I told you—I’m not smart, I’m an athlete.”
“Athletes can’t be smart too?”
“Well, they don’t have to. I’m gonna play basketball in college, and all you really need to get in on an athletic scholarship is a C.”
Then I show him an app that another teacher had made—this one is similar in its functionality, but has pictures, text, and audio clips of different people talking about the Ferguson protests. His eyes widen. He takes the tablet from me and starts playing with the buttons.
“I know about this!”
I think at this point in his life, Jake is more excited about making a basketball game app designed to rack up mad points than a Ferguson app designed to provide social commentary. He’s thirteen, after all.
But that’s okay. When he played with the app, he saw people that looked like him. He didn’t see a KEEP OUT sign.
The next week, Jake was a little more engaged in the lesson. He got further than some other kids on that day’s tutorial, and even gave them pointers on fitting the blocks together. They went back and forth between their workstations, laughing at the sounds they could make the tablets produce, playfully chiding each other’s screwups, and peering at how the next kid fit her blocks together.